998 Scoring Dimensions. 254 Tests. Your Hardware.
Everything AiBenchLab does, organized by category. No marketing — just what's built, what tier it requires, and what it does.
998
Scoring Dimensions
998 ways to prove an AI model can — or can't — do the job
254
Tests
Across 11 domains from reasoning to adversarial safety
10
Providers
Built-in llama.cpp, Ollama, LM Studio, LocalAI, OpenAI, Anthropic, Gemini, Grok, Groq + custom
22
Suites
Pre-built evaluation suites across 4 categories
Feature Matrix
Every feature × every tier. Tiers are cumulative — each includes everything to its left.
✓ included — not in this tier value = the cap / state for that tier
14d
Trial is not a tier. New installs begin with a 14-day Pro trial — full Pro power unlocked. After 14 days it settles into Limited Mode. No hard-lock; keeps working forever. White-label & commercial rights require Pro or Agency.
| Feature | Limited | Pro | Agency | Enterprise |
|---|---|---|---|---|
| Core Benchmarking Engine | ||||
| Eval engine · composite Score · domain breakdown | ✓ | ✓ | ✓ | ✓ |
| Per-test scoring · pass/fail · anomaly detection | ✓ | ✓ | ✓ | ✓ |
| Empirical context-window validation | ✓ | ✓ | ✓ | ✓ |
| Fixed-seed runs · hardware fingerprint | ✓ | ✓ | ✓ | ✓ |
| Latency metrics · hardware-efficiency analysis | ✓ | ✓ | ✓ | ✓ |
| Wizard · Recommendation · Models | ||||
| 8-step wizard · live monitor · in-wizard cost estimate | ✓ | ✓ | ✓ | ✓ |
| Recommendation engine (VRAM fit · intent · budget) | ✓ | ✓ | ✓ | ✓ |
| All local models (llama.cpp · Ollama · LM Studio · CUDA · Vulkan) | ✓ | ✓ | ✓ | ✓ |
| All cloud models — bring your own key | ✓ | ✓ | ✓ | ✓ |
| Full model catalog & discovery | ✓ | ✓ | ✓ | ✓ |
| Wizard client-name field | — | — | ✓ | ✓ |
| Test Suites | ||||
| Reasoning · Code · Chat (3 core) | ✓ | ✓ | ✓ | ✓ |
| Deployment Risk · Adversarial Safety · Tool Calling | — | ✓ | ✓ | ✓ |
| Multimodal · Multi-Turn · Agentic | — | ✓ | ✓ | ✓ |
| Per-run enable/disable tests | ✓ | ✓ | ✓ | ✓ |
| Custom suite creation from built-in tests + save + version lock | — | ✓ | ✓ | ✓ |
| Custom test creation (consultant-grade) | — | — | ✓ | ✓ |
| Comparison & History | ||||
| Models compared per session | 3 | 10 | Not limited* | Not limited* |
| Side-by-side · domain-by-domain · mix local+cloud | ✓ | ✓ | ✓ | ✓ |
| Saved session history (local, your data) | Not limited* | Not limited* | Not limited* | Not limited* |
| Export & Reporting | ||||
| PDF report branding | Watermarked | Branded | White-label | White-label |
| Full professional report (cover · charts · latency · cost · appendices) | — | ✓ | ✓ | ✓ |
| CSV export (spreadsheet analysis) | — | ✓ | ✓ | ✓ |
| MBX export (verification artifact) | ✓ | ✓ | ✓ | ✓ |
| Standalone cost-report PDF (AiBenchLab-branded) | — | ✓ | ✓ | ✓ |
| JSON full-audit export (the report-generation feed) | — | — | ✓ | ✓ |
| Batch export (mass report production) | — | — | ✓ | ✓ |
| Custom logo · "Prepared For" client name · business profile | — | — | ✓ | ✓ |
| Commercial client-delivery rights | — | — | ✓ | ✓ |
| Advanced MBX integrity verification | — | — | — | ✓ |
| Automation — Run Queue | ||||
| Manual run queue + controls (stop / delete / requeue) | ✓ | ✓ | ✓ | ✓ |
| Headless Automation — CLI · API · MCP (separate download) | ||||
| CLI — headless runs · scripting · JSON out | — | — | ✓ | ✓ |
| REST API — execute · list · export · status | — | — | ✓ | ✓ |
| MCP integration — remote control from AI tools | — | — | ✓ | ✓ |
| Hardware Safety · Security · Setup | ||||
| Thermal protection · cooldown · VRAM monitoring | ✓ | ✓ | ✓ | ✓ |
| Tamper detection · encrypted local keys · local-first design | ✓ | ✓ | ✓ | ✓ |
| Component manager · on-device judge · first-run setup | ✓ | ✓ | ✓ | ✓ |
| Built-in plugin management + integrity validation | ✓ | ✓ | ✓ | ✓ |
| Enterprise Compliance & Audit | ||||
| Complete audit trail (every action logged) | — | — | — | ✓ |
| Tamper-evident integrity (SHA-256 hash chain) | — | — | — | ✓ |
| Chain of custody reports | — | — | — | ✓ |
| Audit CLI commands | — | — | — | ✓ |
| SIEM-compatible exports (JSON/CSV) | — | — | — | ✓ |
| Integrity verification command | — | — | — | ✓ |
| Offline activation (air-gapped deployment) | — | — | — | ✓ |
| Deployment & Licensing | ||||
| Seats | 1 | 1 | 3 | 10+ (custom) |
| Custom test plugins | — | — | — | ✓ |
| Procurement (PO/invoice · MSA · custom terms) | — | — | — | ✓ |
| Support SLA · account manager · onboarding | — | — | — | ✓ |
| Commercial | ||||
| License model | Limited Mode | Lifetime | Lifetime | Annual |
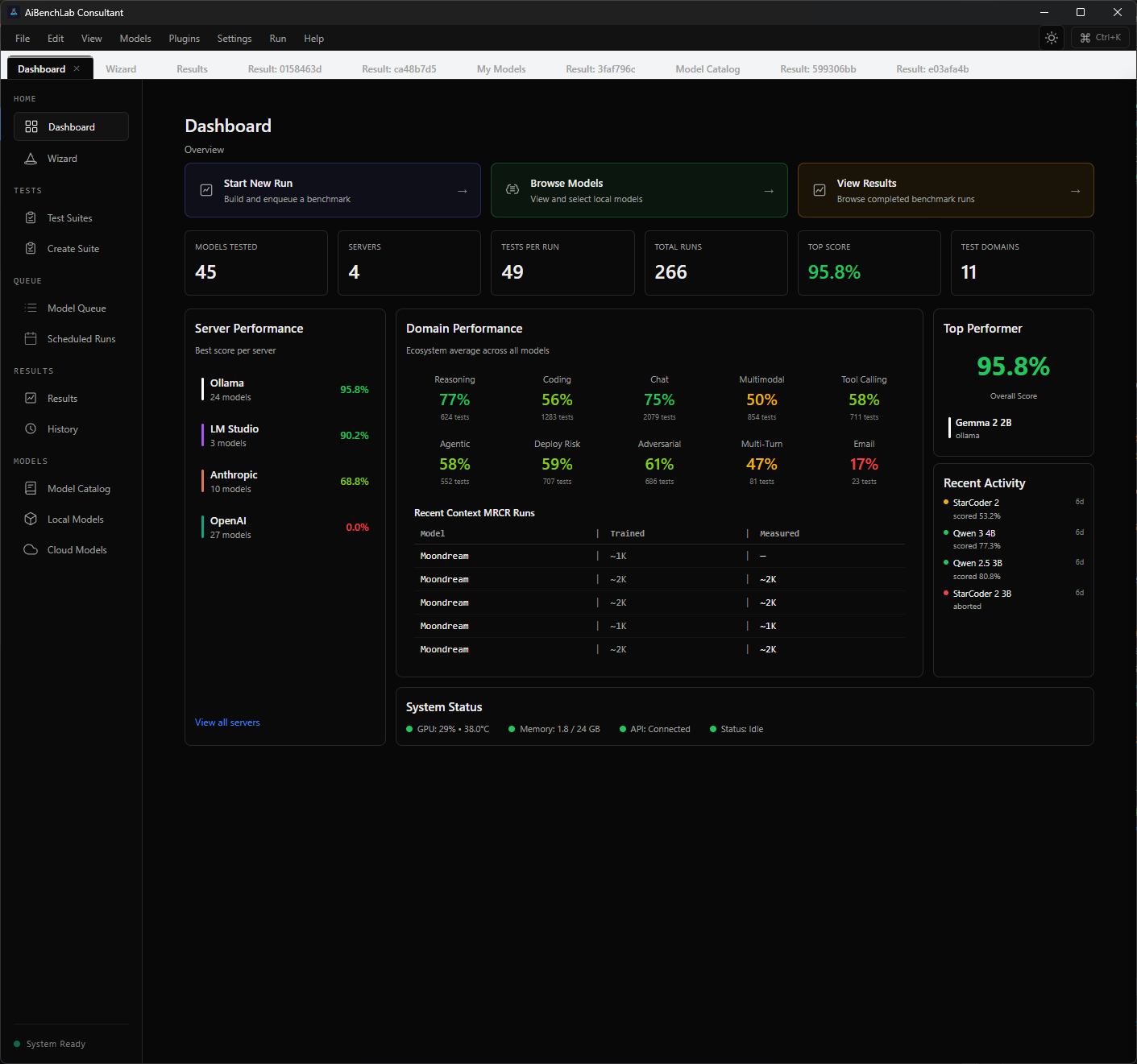
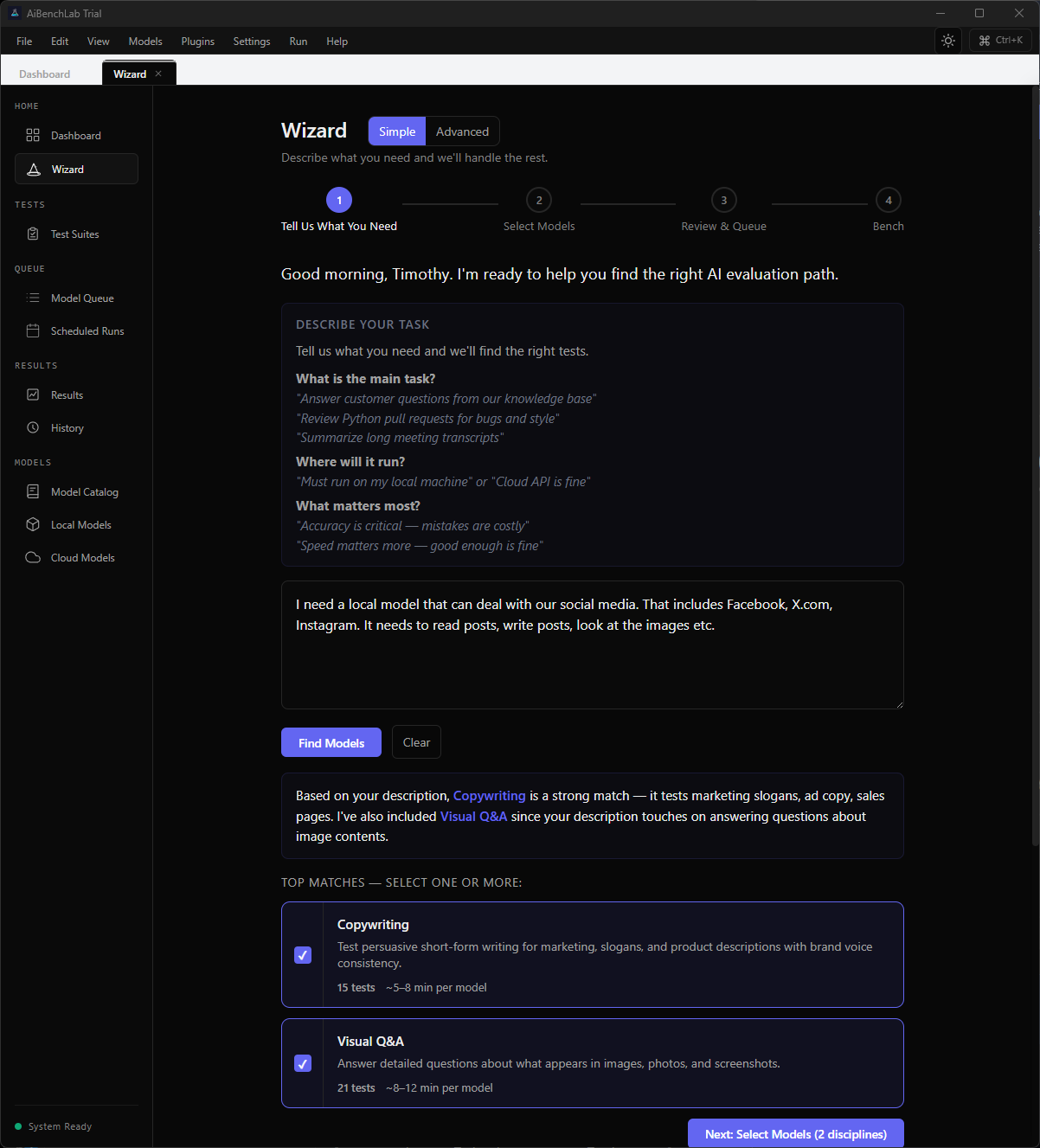
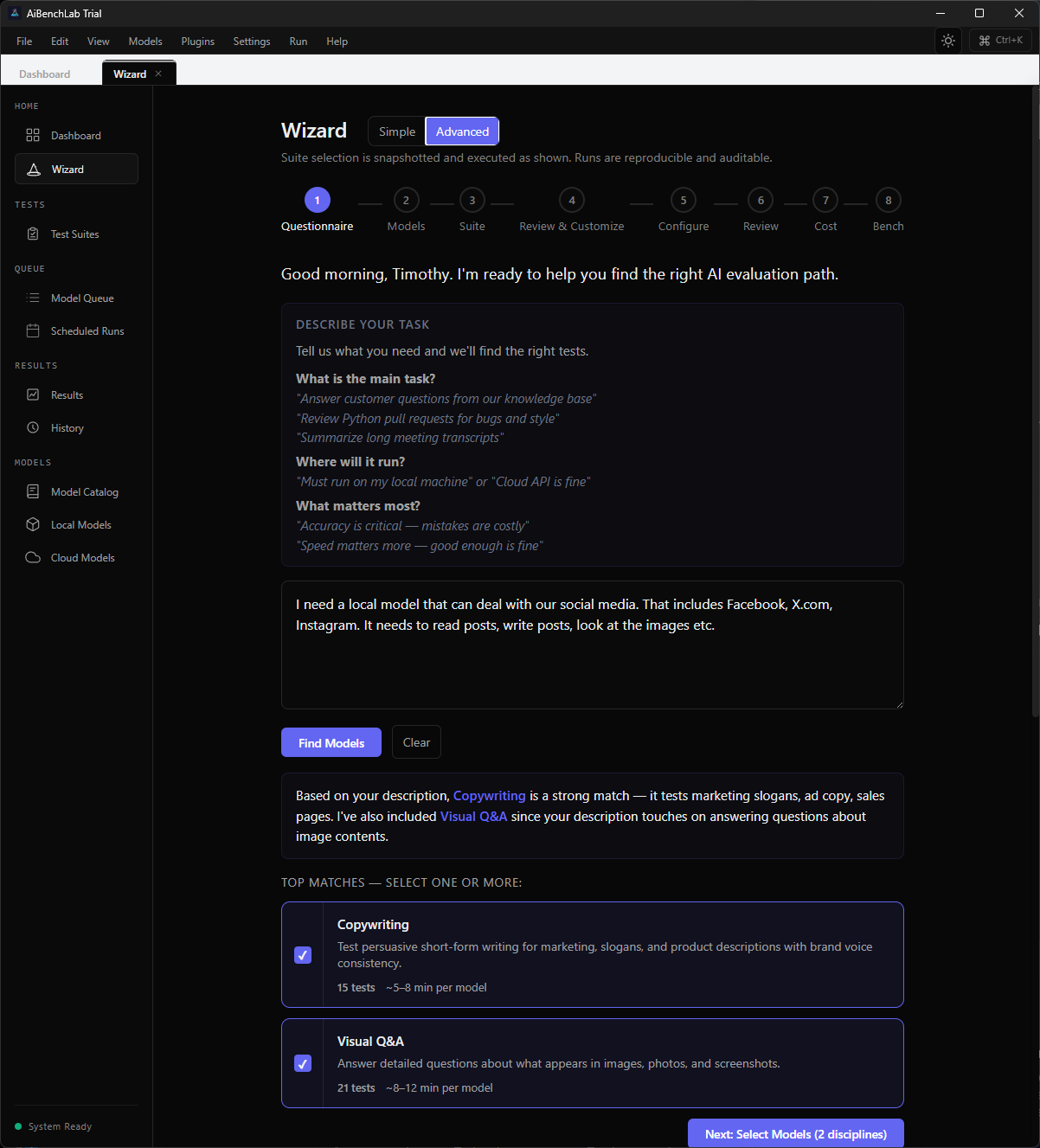
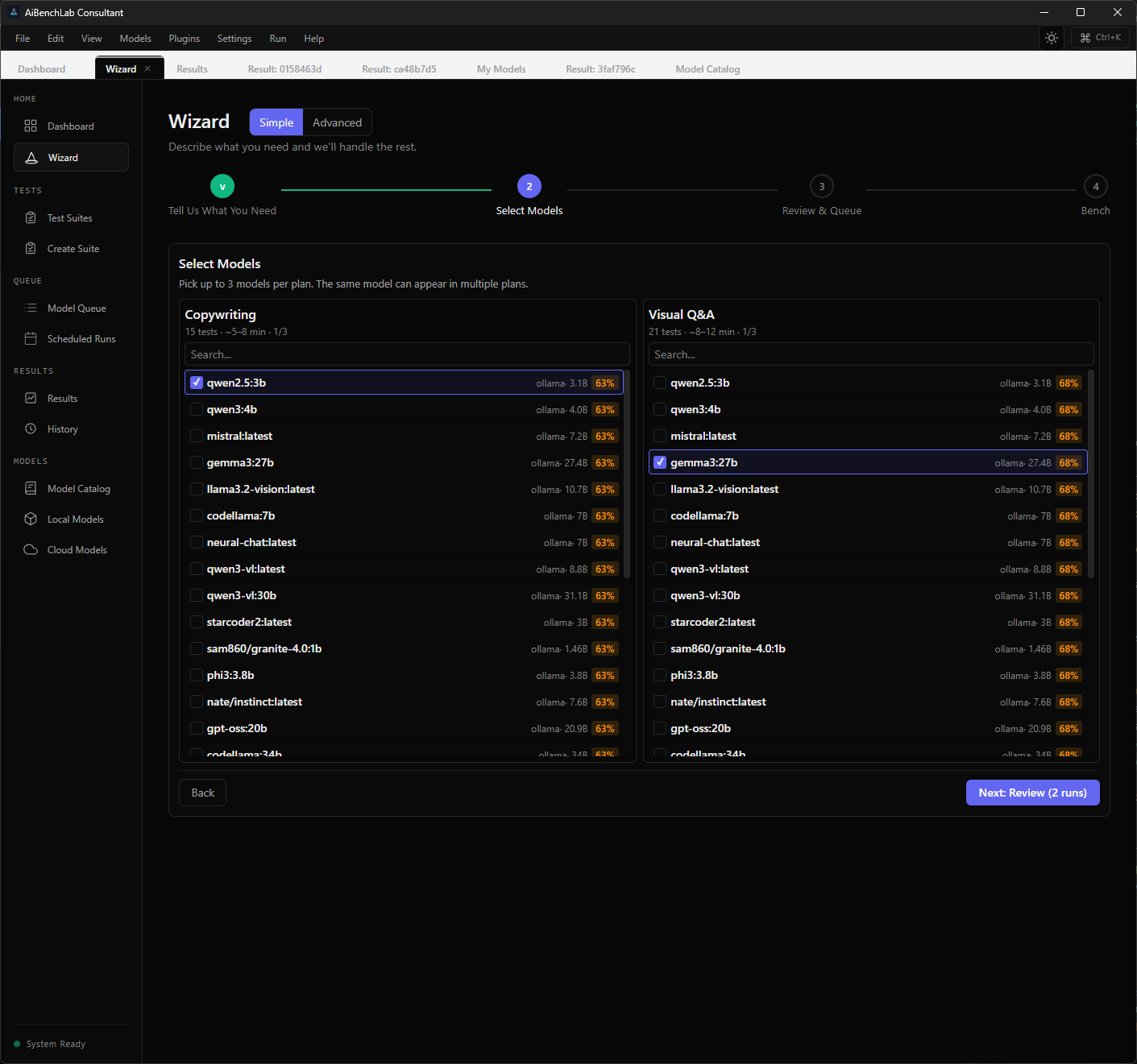
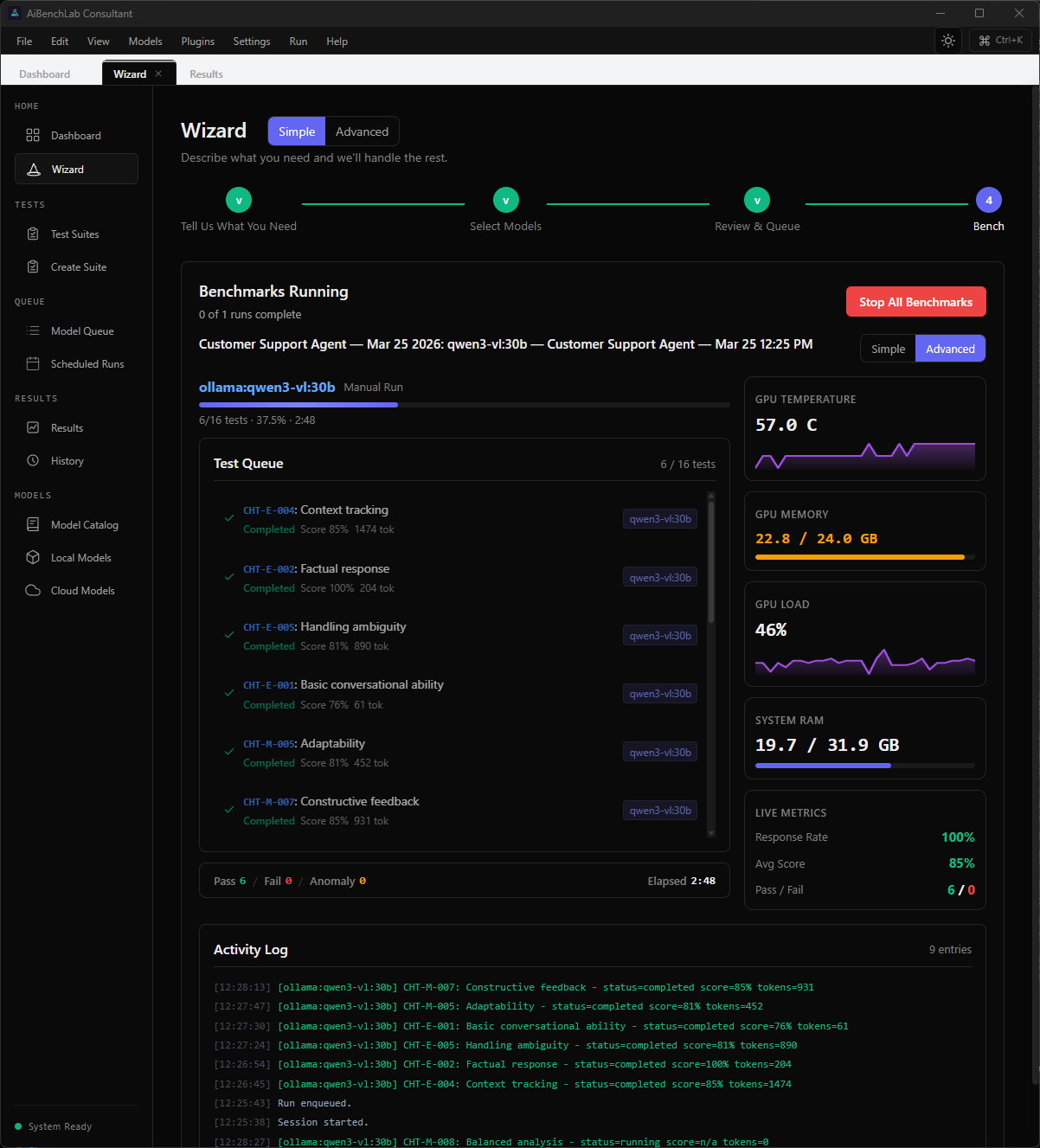
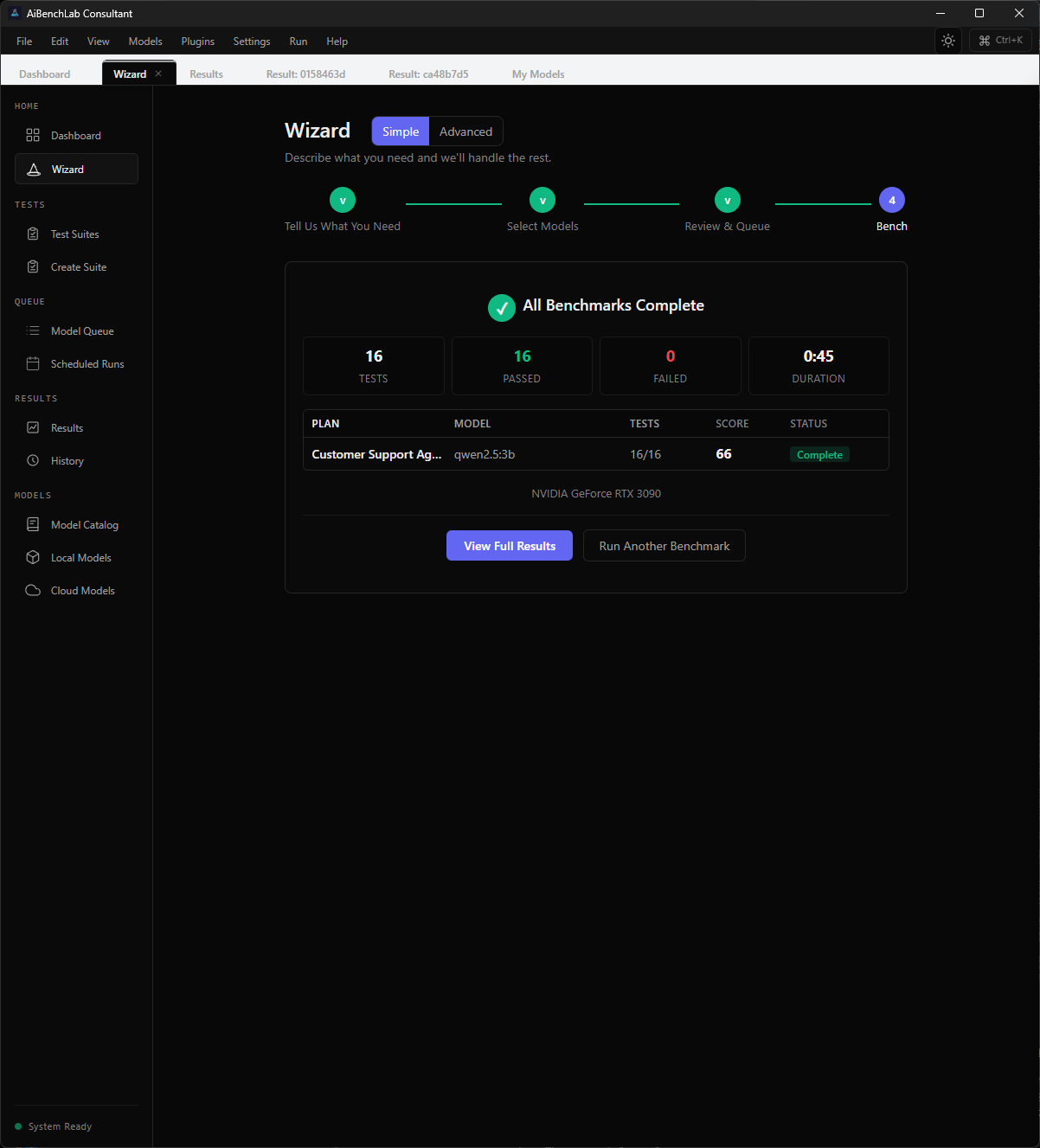
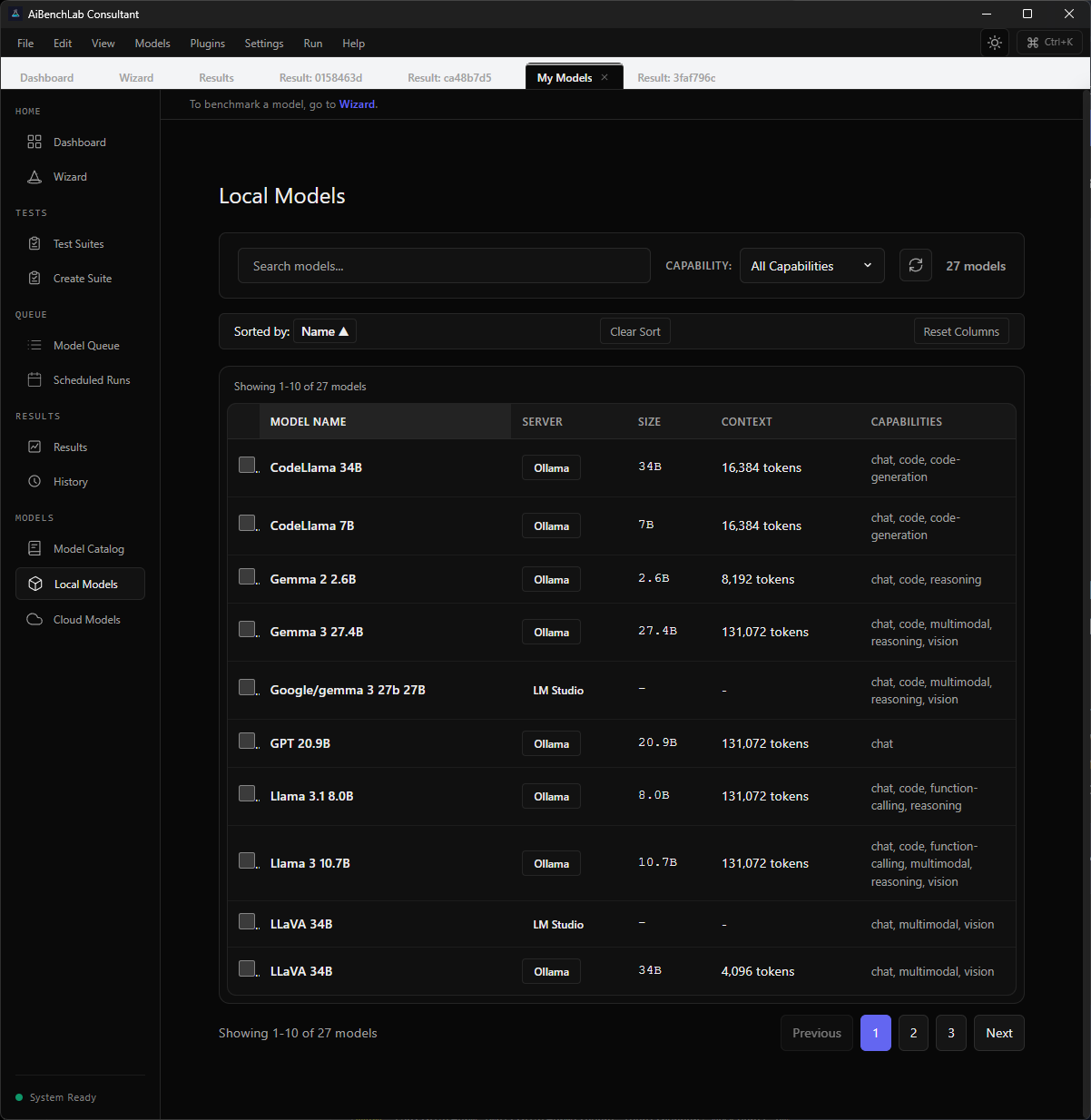
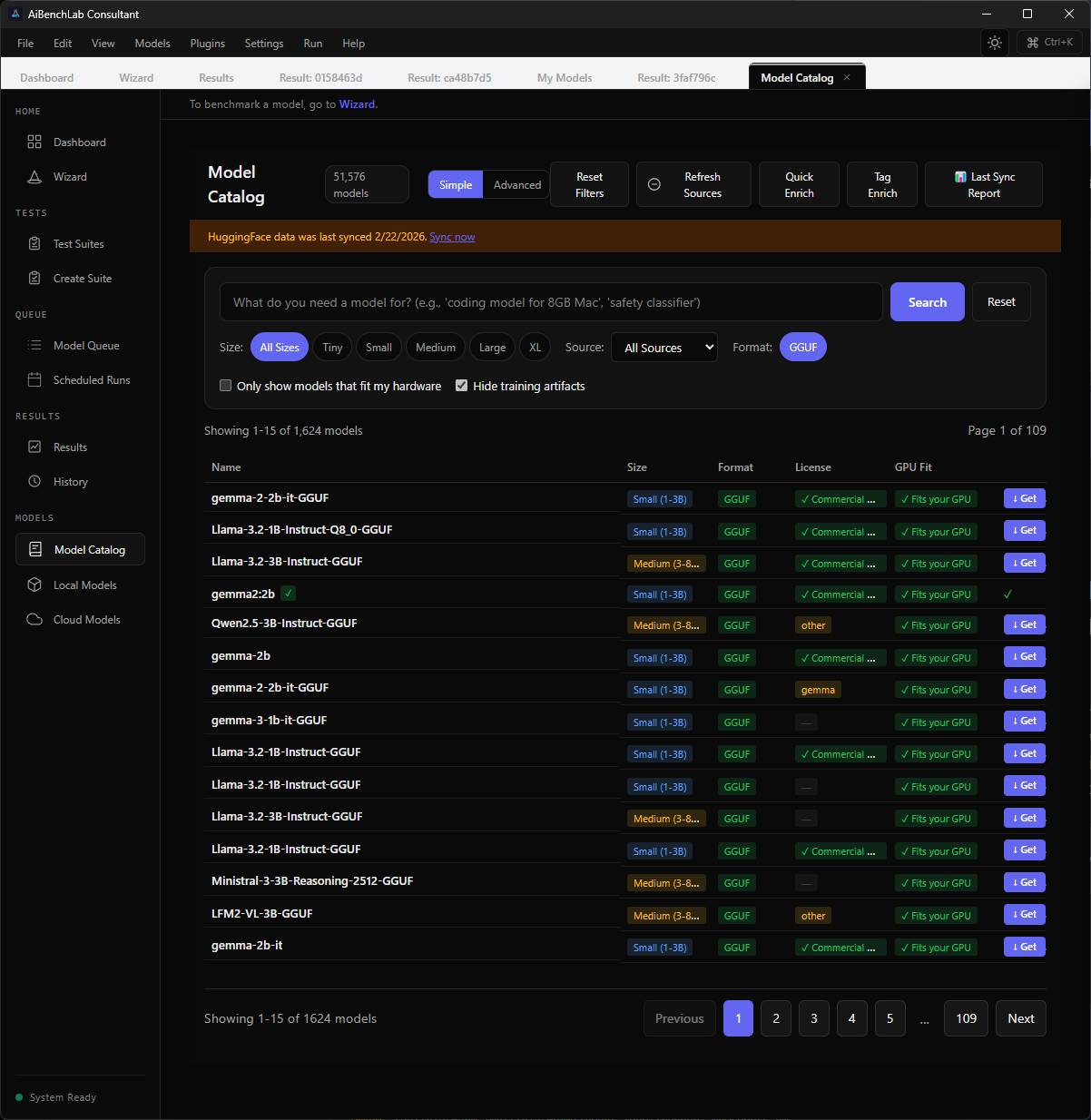
Screenshots
Don't pay for another AI model until you know it can do the job.
Start your 14-day Pro trial today — no credit card required.