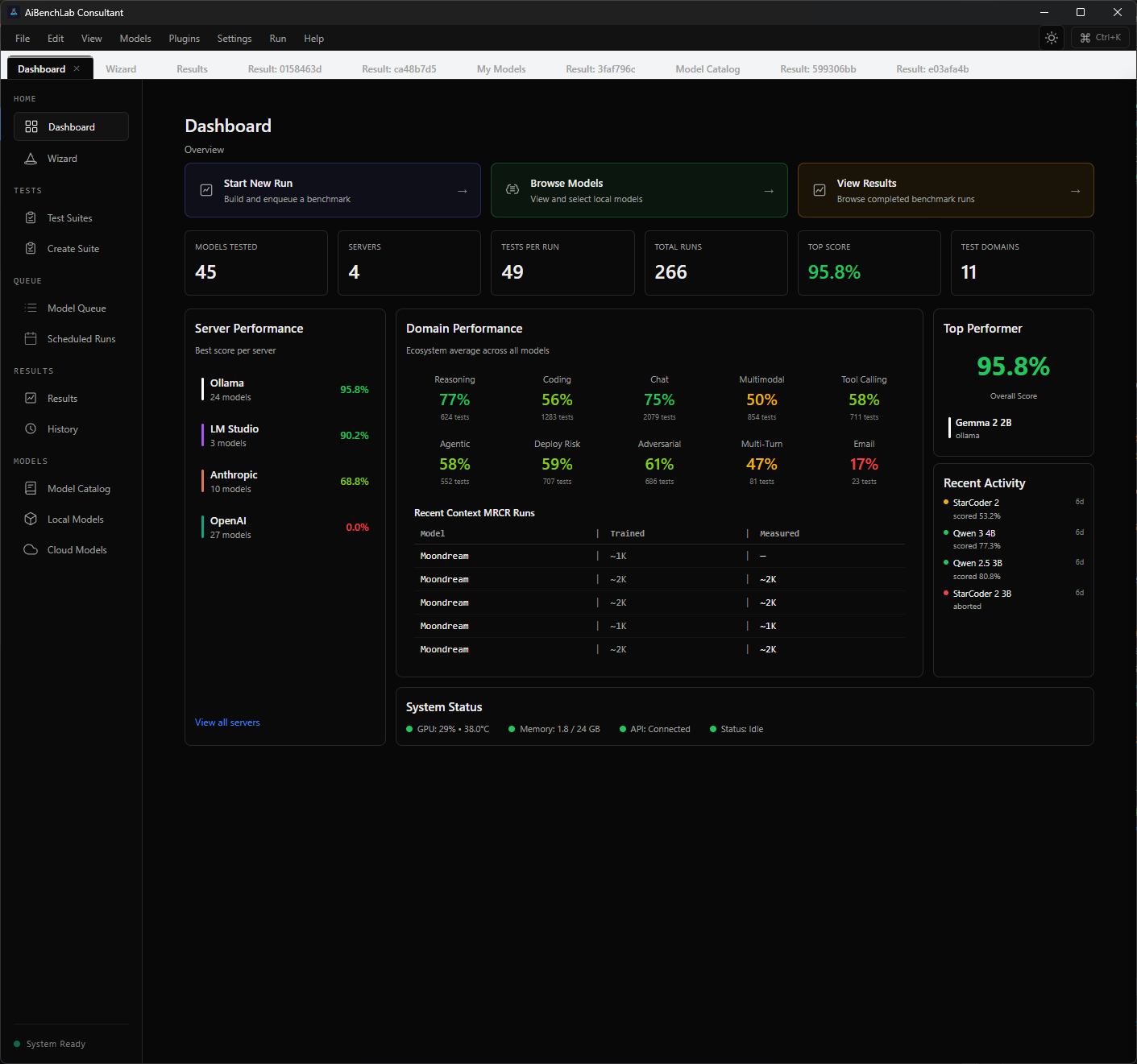
Stop guessing which AI model works. Prove it.
254 tests, 11 domains, 998 scoring dimensions — compare, and deploy with confidence. On your hardware. Nothing leaves your machine.
The cost of guessing is higher than the cost of testing.
998 dimensions of proof. No AI model hides from that.
See how AI models actually perform — benchmarked locally, nothing leaves your machine.
Next release in preparation — Windows first, macOS & Linux to follow.
Local-First
Your hardware, your data. Benchmark content — prompts, model outputs, results, and API keys — never leaves your machine. Optional crash diagnostics can be disabled.
Your Data Stays Yours
We never see your prompts, model outputs, or benchmark scores. The only data we collect is what's needed for your account, payments, support, and optional disableable diagnostics. Details in our Privacy Policy.
Continuously Updated
New test domains, new suites, new metrics. The AI landscape moves fast — AiBenchLab keeps up.
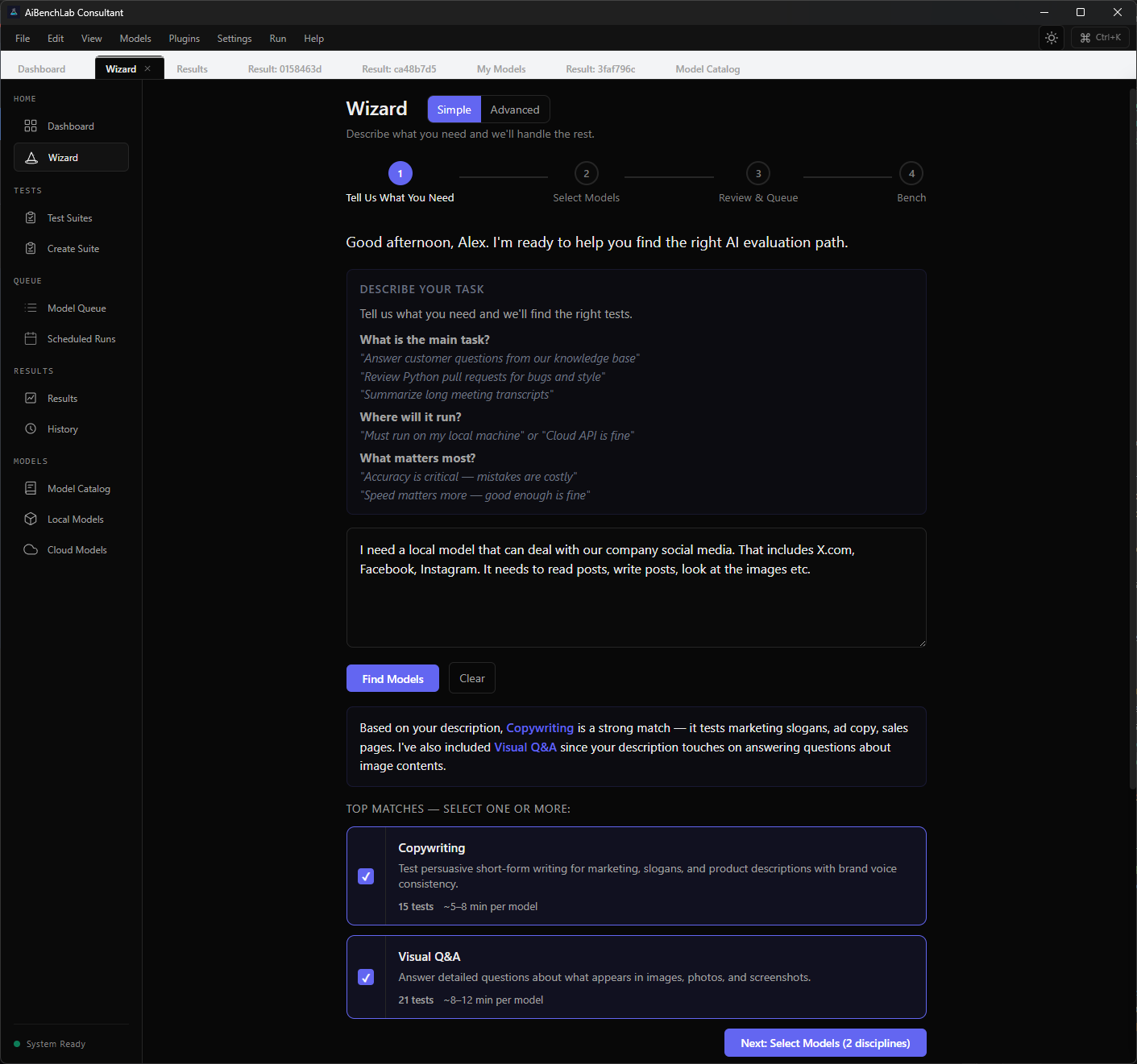
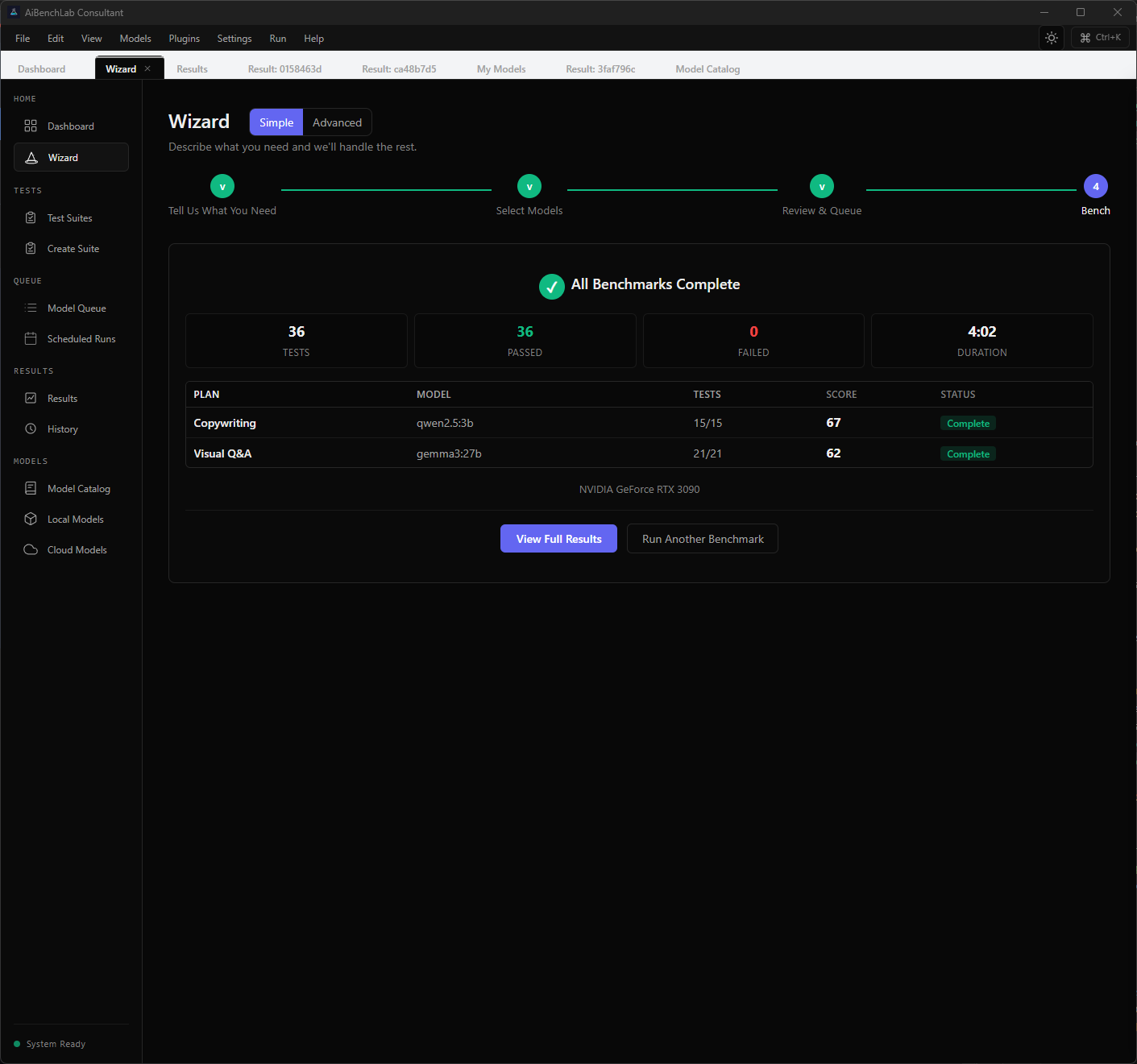
Describe your task. The AI knows what to test.
Type what you need in plain English. The wizard classifies your intent, matches the right evaluation disciplines, and builds a test plan — before you run a single benchmark.
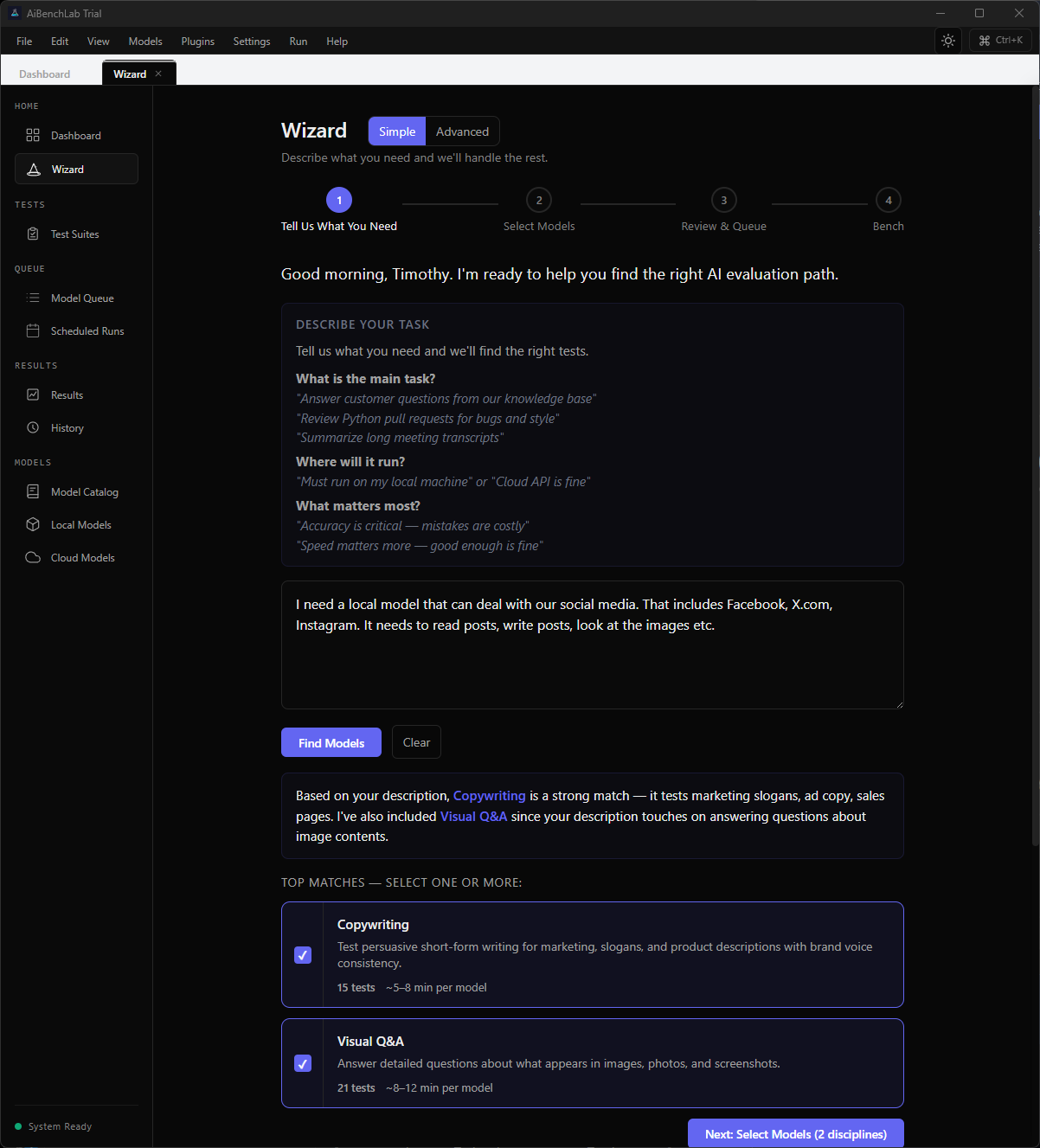
Describe your task in plain English. The AI matches the right disciplines, estimates time, and gets you testing in minutes. Four steps, no guesswork.
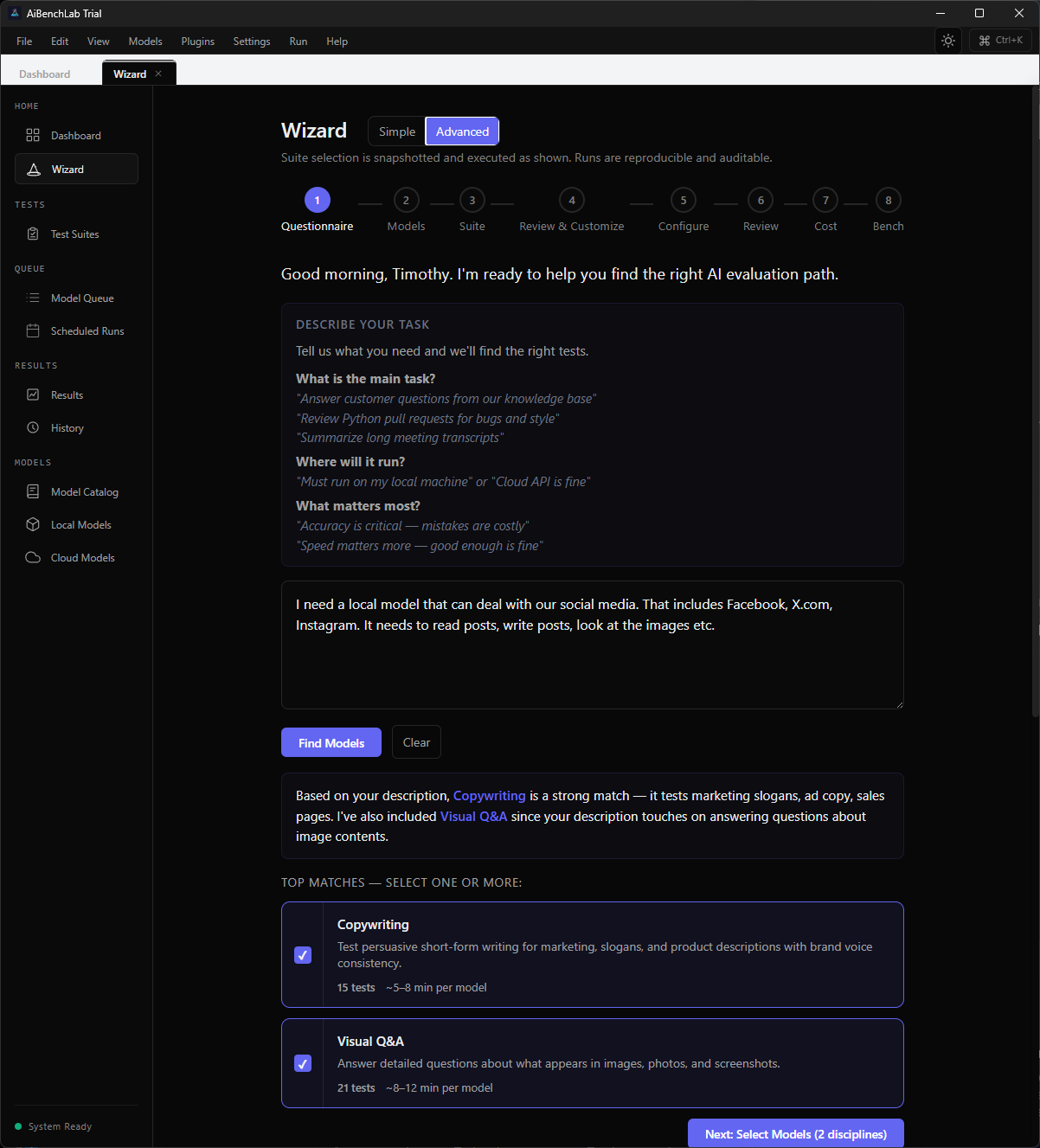
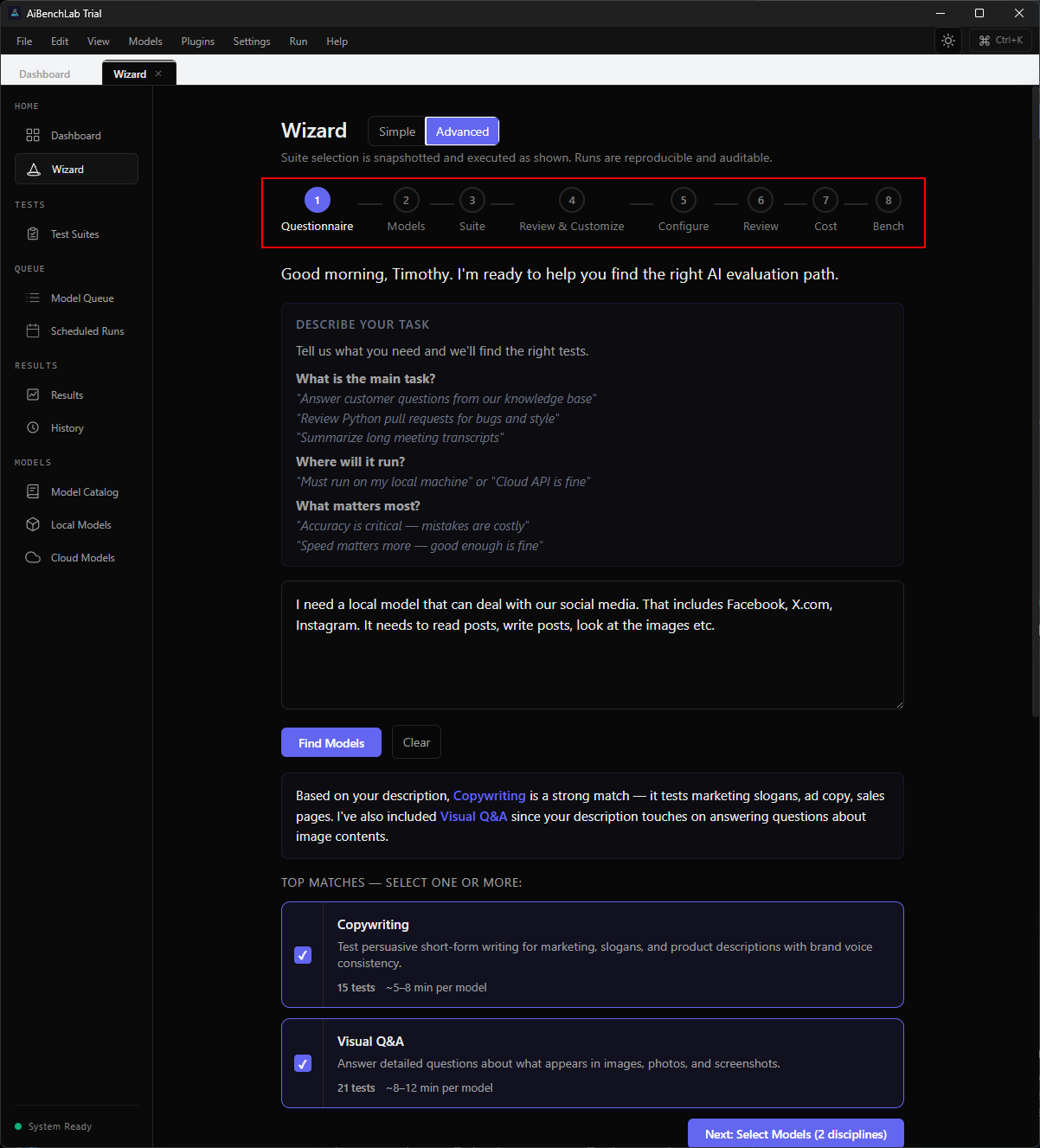
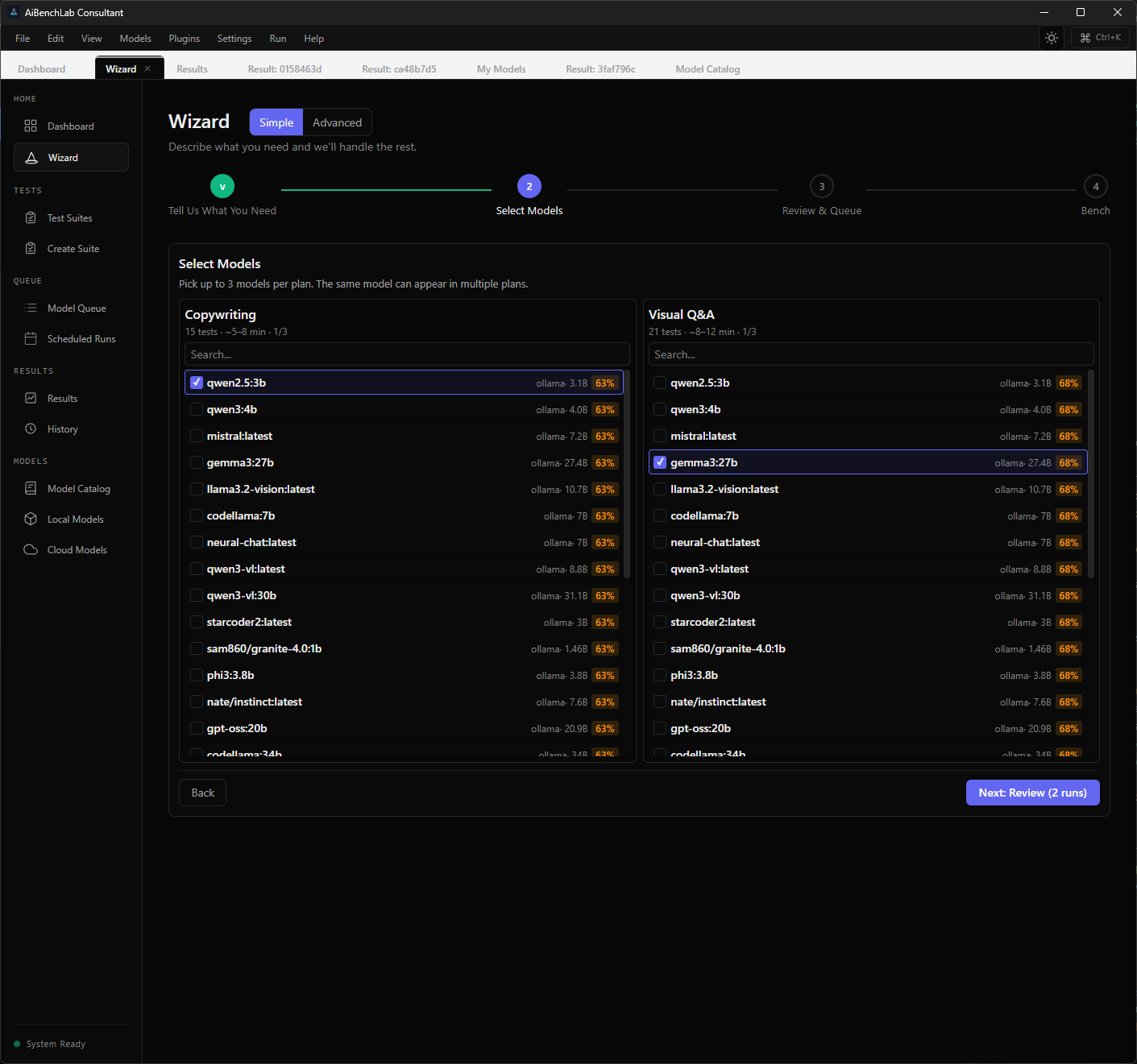
Full control over every step. Eight-stage workflow — questionnaire, model selection, suite customization, configuration, review, cost estimation, and execution. Reproducible, auditable, snapshotted.
Same wizard. Same intelligence. You choose how deep to go.
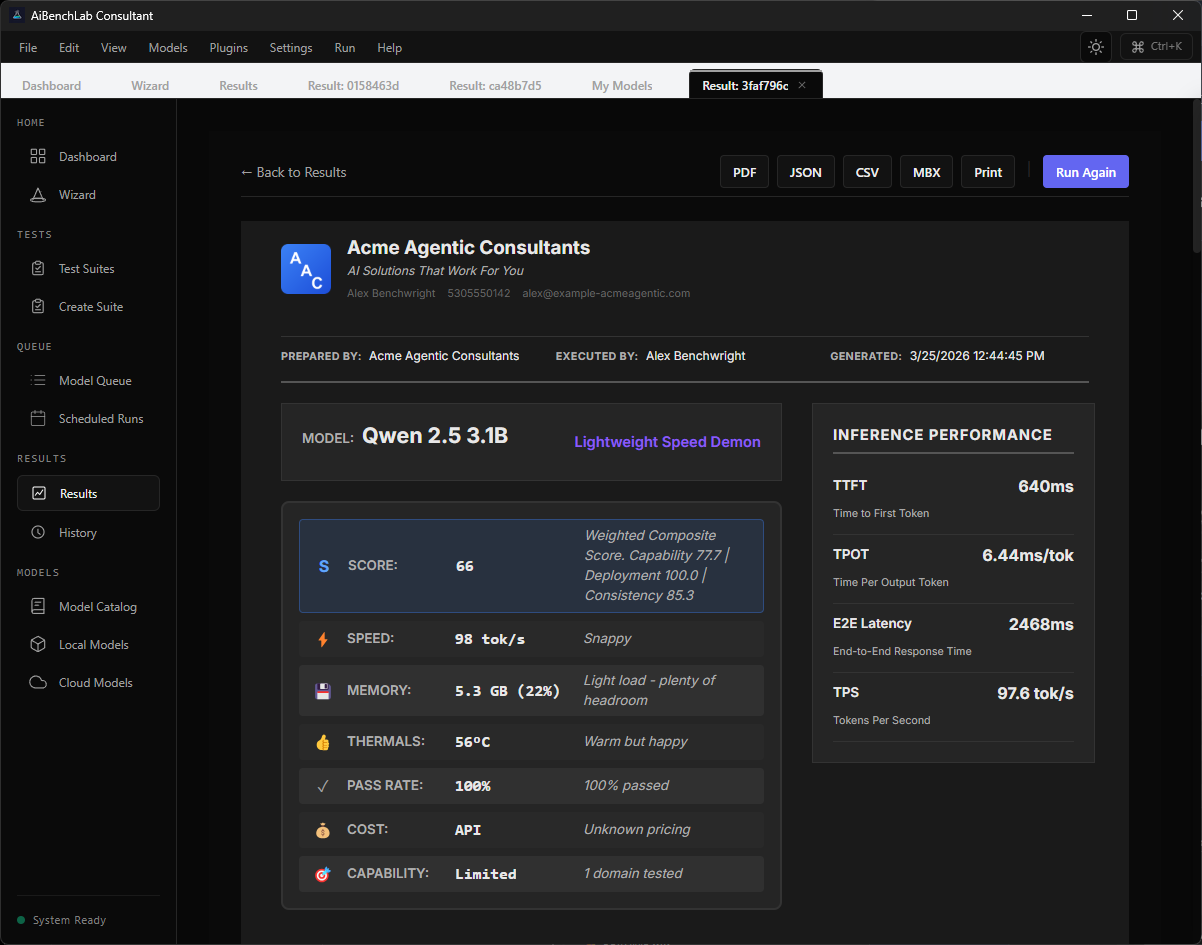
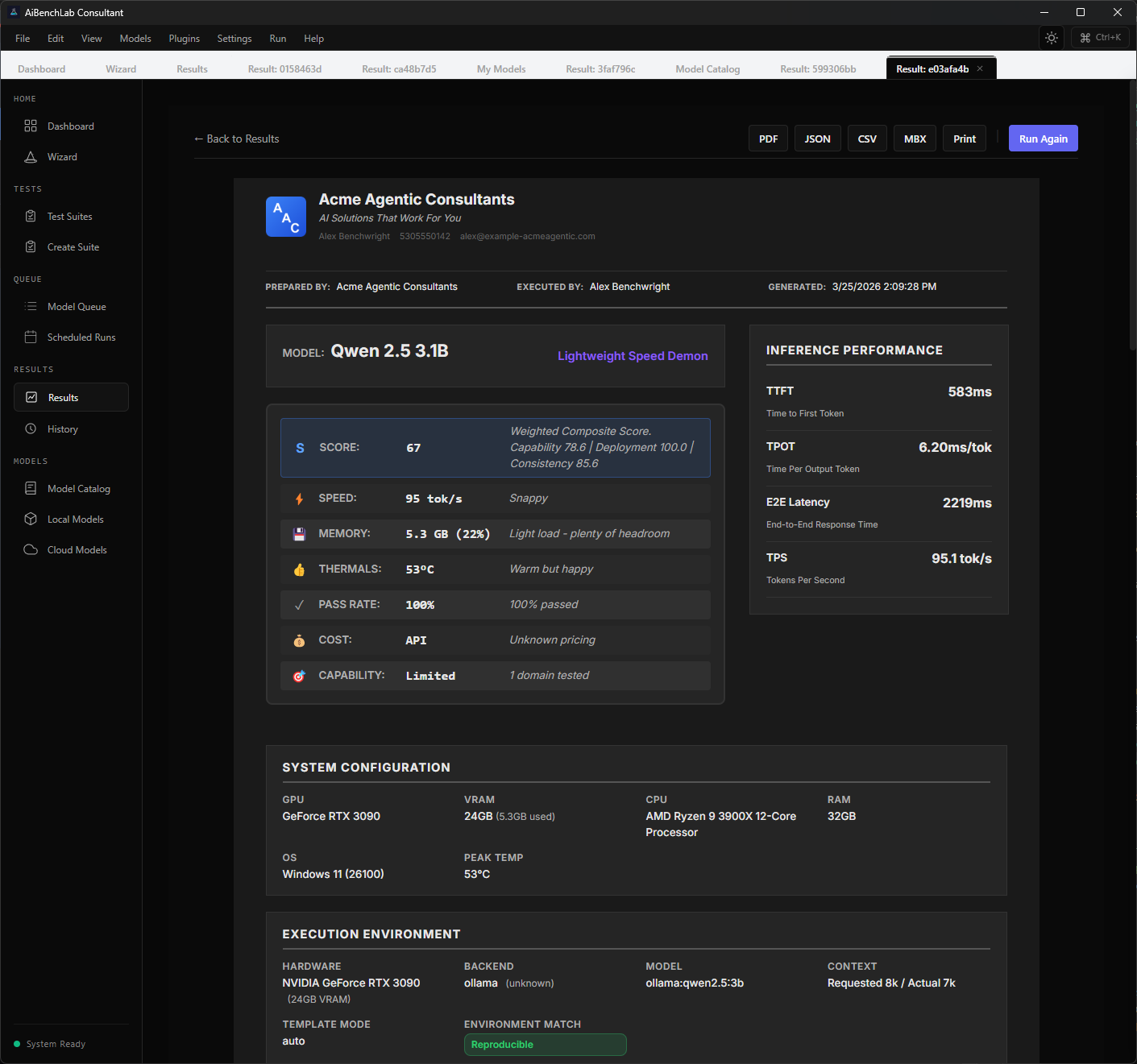
Real numbers, not marketing.
How fast the model starts responding. Critical for interactive use.
How fast it generates each token. Determines real-time experience.
Overall throughput speed. How much work it can handle.
Total time from prompt to complete response. The metric users feel.
Find it. Fit it. Test it.
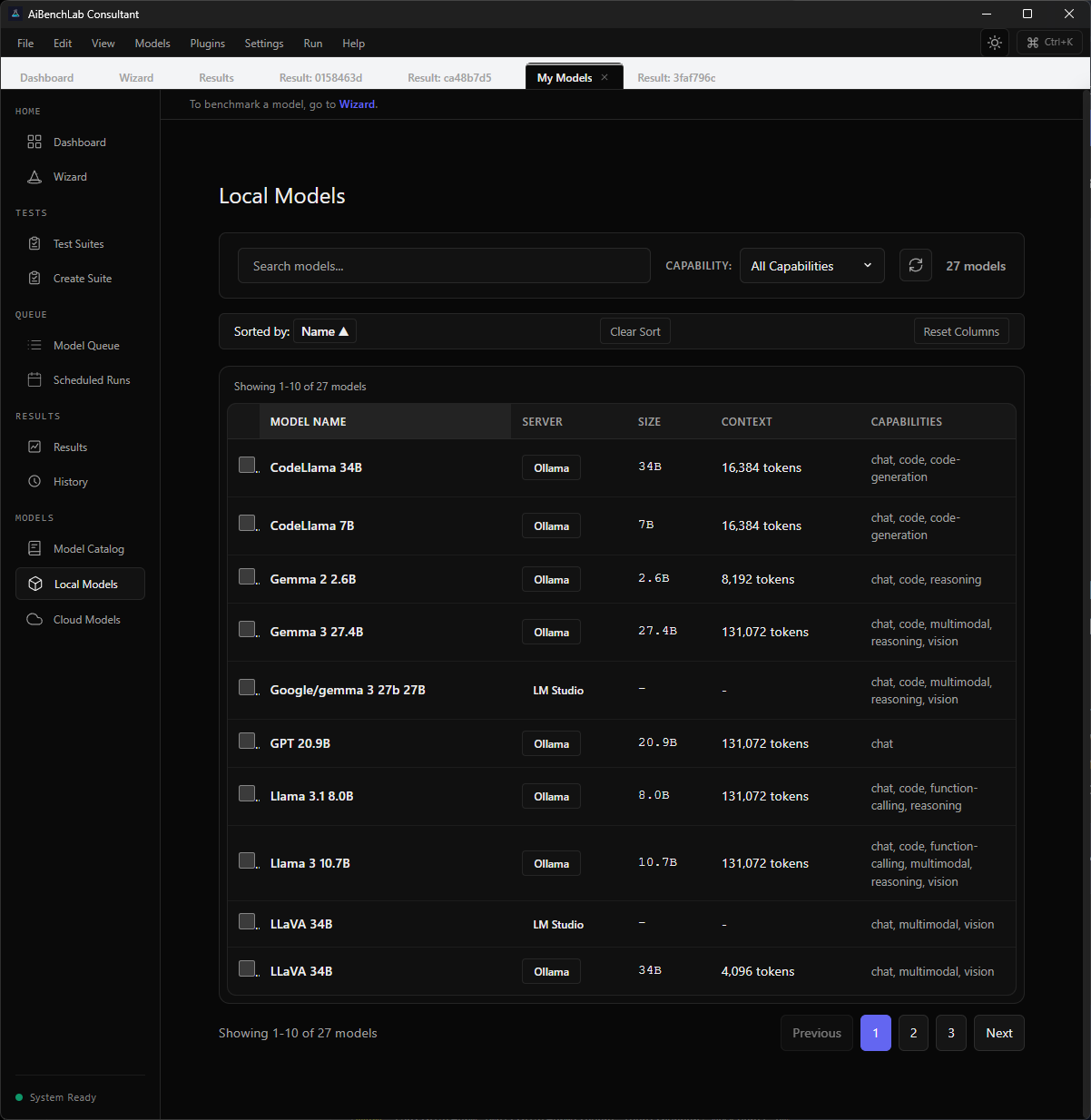
Browse 51,000+ models from HuggingFace and local providers. Filter by size, format, license, and GPU fit — then download and benchmark without leaving the app. Your local models from Ollama and LM Studio are detected automatically.
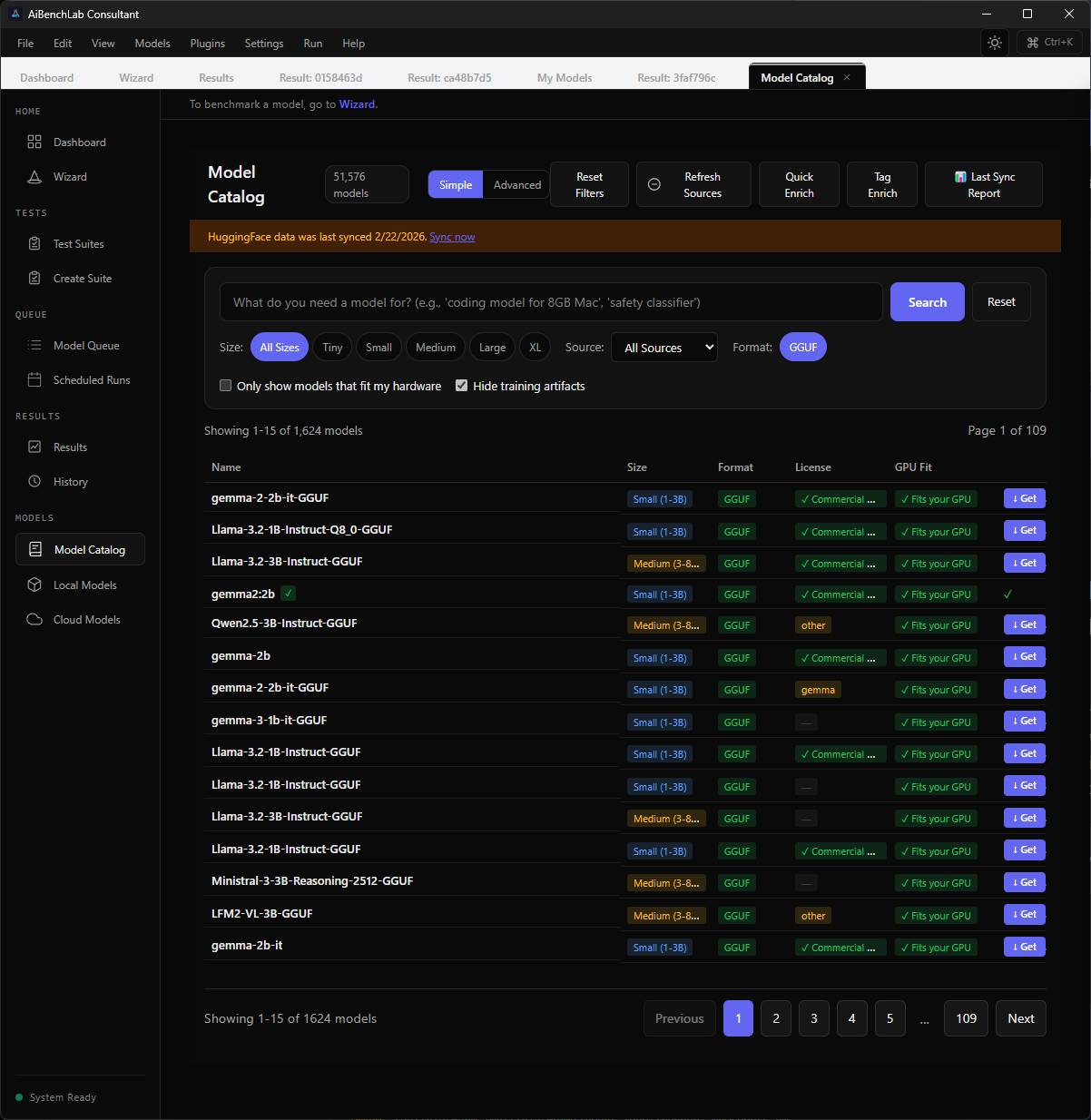
998 dimensions of proof. No AI model hides from that.
998 scoring dimensions across 254 tests and 11 domains. Every domain tests a different dimension of model capability. Together, they give you the complete picture.
Every test contains multiple scoring criteria — measuring not just whether the model answered, but how well it answered across every dimension that matters.
Reasoning
30Logic, math, probability, constraint satisfaction, meta-reasoning
Coding
35Algorithms, data structures, concurrency, systems programming, edge cases
Chat
25Conversation quality, format compliance, creativity, empathy, bias detection
Multimodal
30Image understanding, OCR, charts, diagrams, medical imagery, satellite
Tool Calling
33Function calling accuracy, parallel/sequential, error recovery, fault tolerance
Agentic
27Goal decomposition, multi-agent coordination, state management, autonomous troubleshooting
Deployment Risk
28Safety refusals, prompt injection defense, PII handling, jailbreak resistance
Adversarial Safety
30Role-play bypass, authority injection, sycophancy, obfuscated attacks, instruction conflicts
Multi-Turn Adversarial
8Gradual escalation, persona persistence, language switching across turns
Agentic Email
1Real-world email inbox management task
Context Retention
7Needle-in-haystack from 8K to 1M tokens
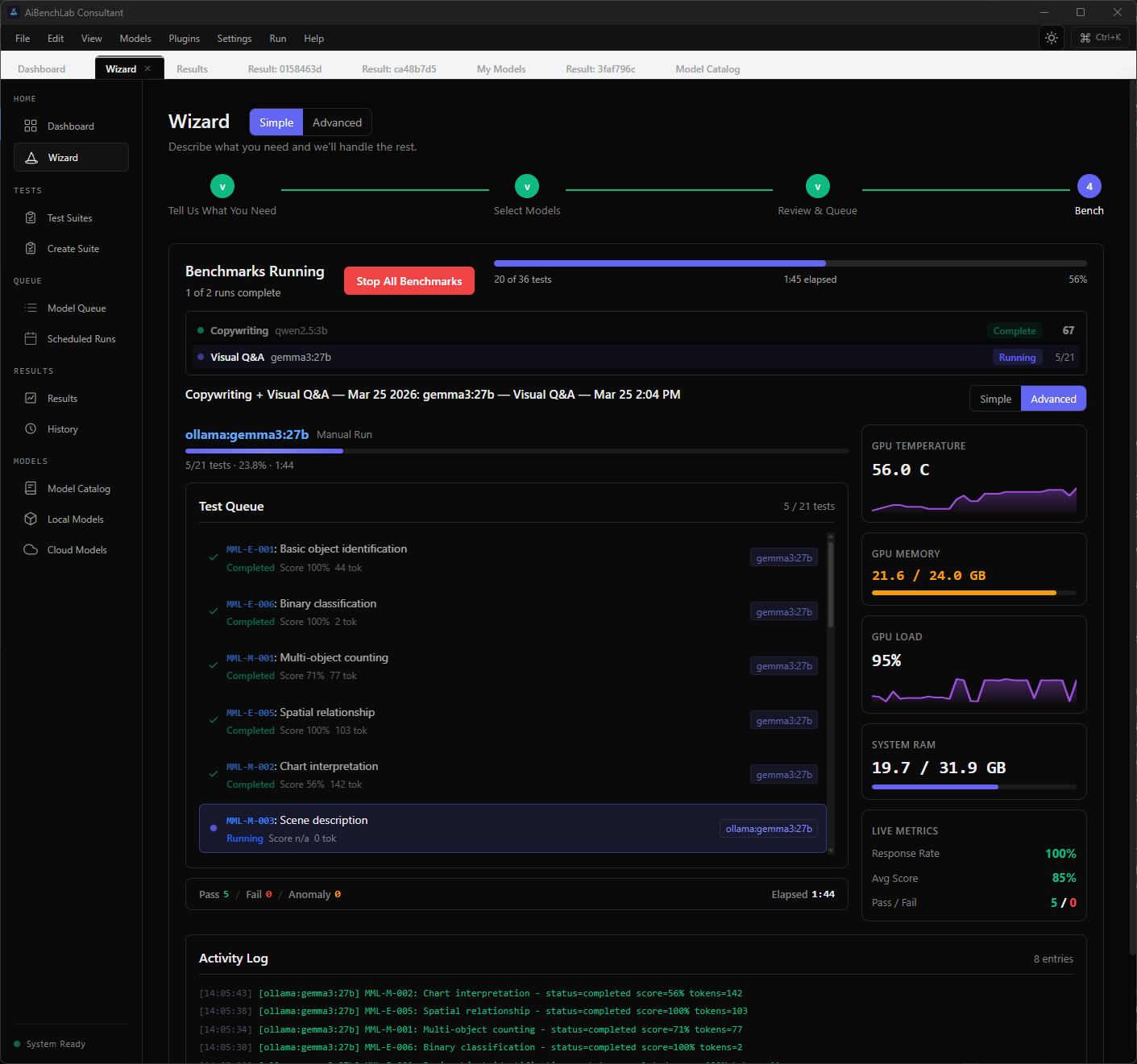
See everything. Miss nothing.
AiBenchLab monitors your GPU temperature, VRAM usage, load, and system RAM in real time while every test runs. Scores, token counts, pass/fail — all visible as they happen. When it's done, you get the full picture in seconds.
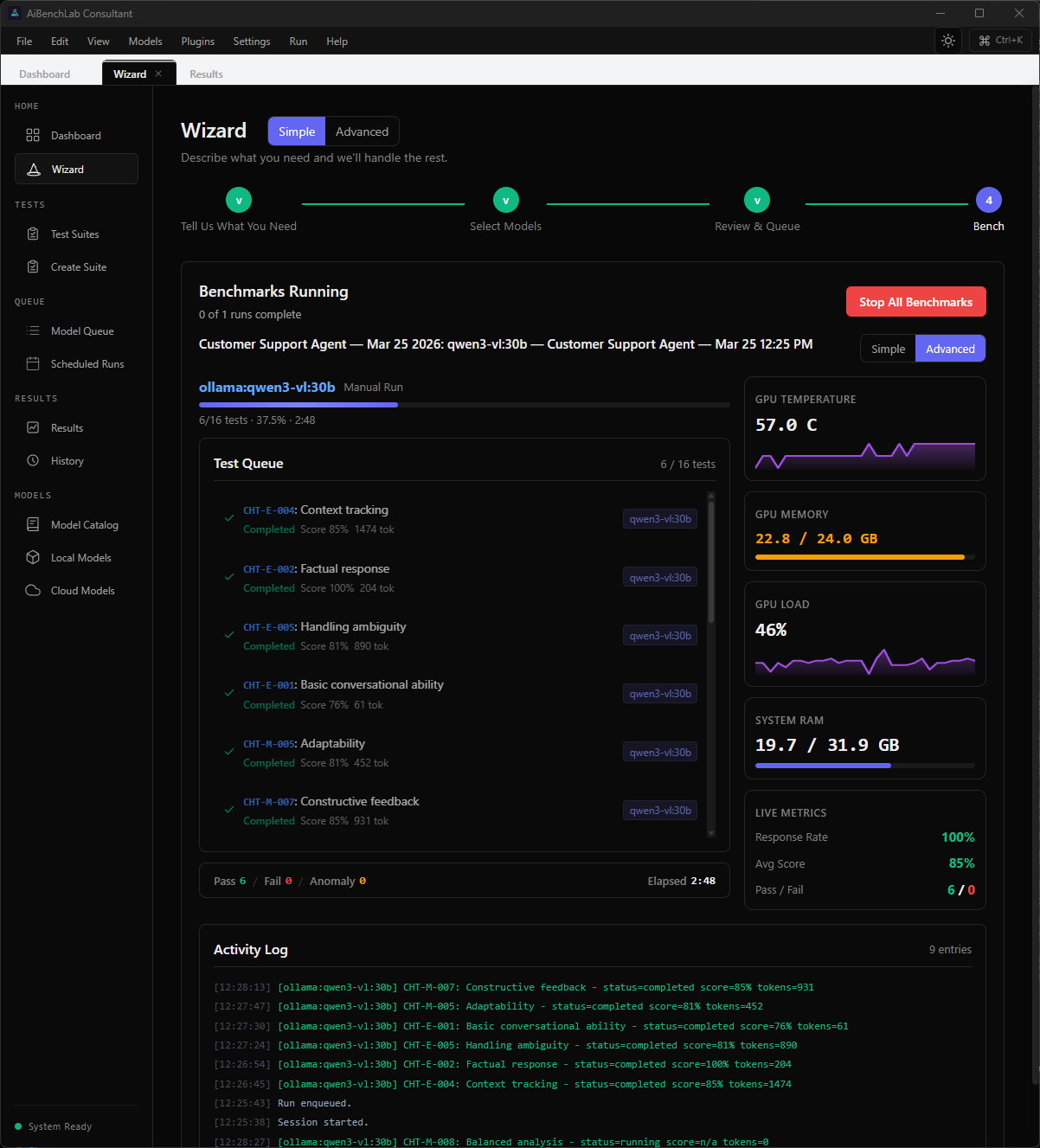
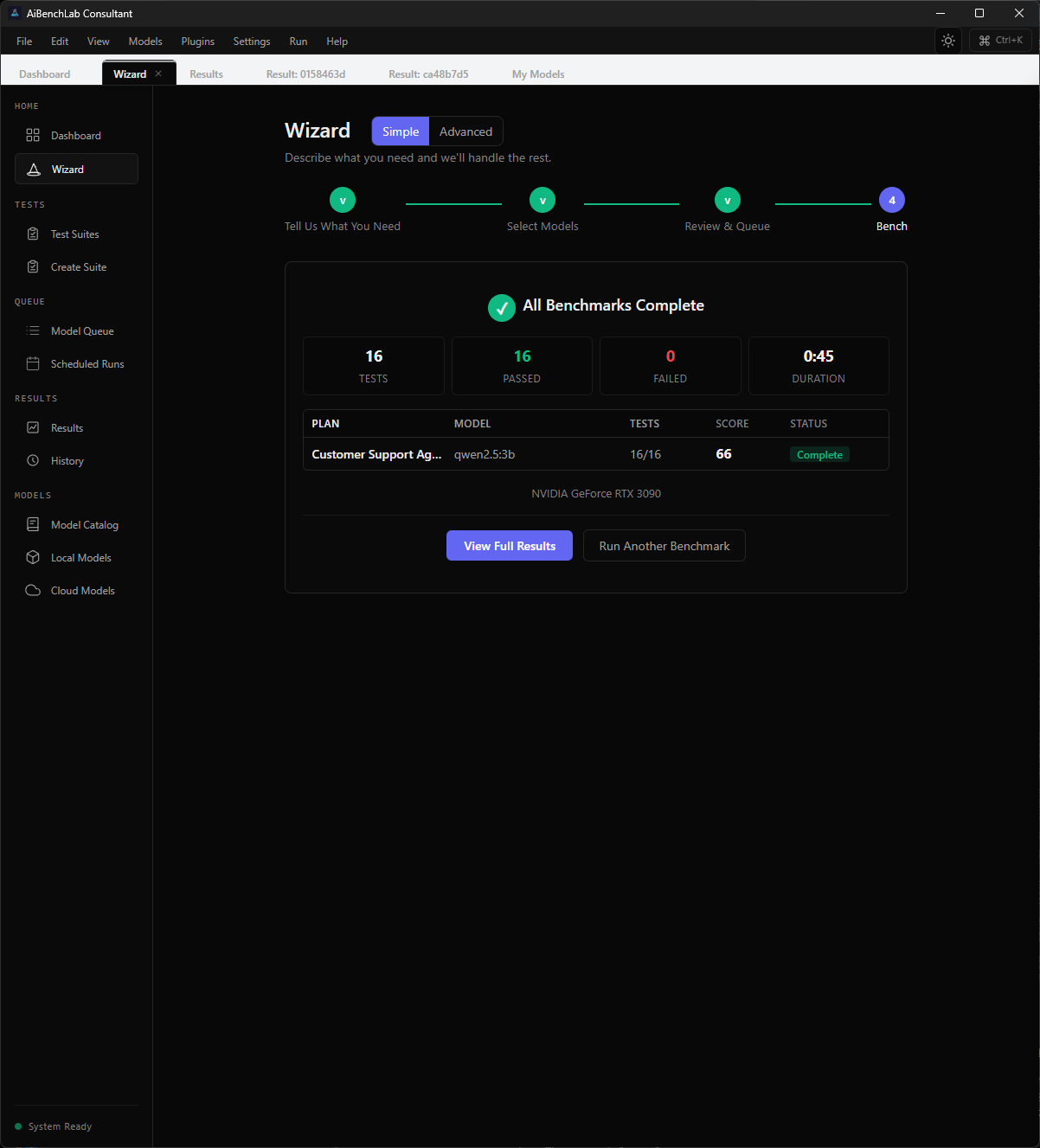
Find the AI that delivers before you waste another dollar.
Save & manage results
Full test history with searchable, filterable results across all sessions.
Side-by-side comparison
Compare models head-to-head on the same tests, same hardware, same conditions.
History & sessions
Track model performance over time. Catch regressions before they reach production.
Exportable reports
PDF reports with executive summaries, forensic breakdowns, and raw data exports.
Deployment-risk scoring
Safety, reliability, and risk scores that tell you whether a model is safe to deploy.
Custom test suites
Build your own test combinations with custom thresholds and scoring criteria.
Get notified about the next release.
Join the waitlist and we'll email you when the next build is ready.
Next Release
The current build is being replaced. Join the waitlist and we'll email you when the new release is available.
Join the WaitlistPaid Plans
All 998 scoring dimensions, 254 tests across 11 domains. Full reporting, all providers, lifetime license.
View PricingHelp businesses stop guessing which AI model to trust.
AiBenchLab is building tools to help people test AI models before wasting money, time, or trust on the wrong one.
We are not hiring full-time positions yet, but we are building a short list of developers, UI/UX people, content helpers, and business or sales collaborators who may be able to help as the company grows.
We may contact selected applicants as contractor, project, or advisory needs come up.
"If you already know which AI model is fastest, cheapest, and most reliable on your machine — you don't need this. Everyone else does."
Stop guessing. Prove which AI is best for your work.
Join the waitlist to be notified when the next release is ready.